



声明:本文译自教授Michael Bronstein在Medium上发布的博客。欢迎大家评论、批评指正翻译中存在的任何问题。
现代机器学习往往忽视了微分几何和代数拓扑的相关知识,在本篇文章中,我会向读者们展示如何以这两个领域的相关知识为有力工具去重新解释图神经网络以及图神经网络模型的一些共同困境。
对称性,无论我们考虑它的广泛或者狭隘定义,它都是人类长久以来用于试图理解和创造秩序、优美和完美的一种理念。
Hermann Wey[1]的这种富有诗意的描述强调了对称性在科学研究中的基石作用。Felix Klein 在1872年的“Erlangen Programme”[2]通过利用对称性来描述了几何学的特征,这不仅仅是数学上的突破,统一了几何学领域而且还进一步导致了现代物理理论的发展,这些理论完全可以追溯到对称的第一原理[3]。在几何深度学习的发展中,类似的原理也出现在了机器学习中,几何深度学习是通过组不变性和等方差性推导出大多数流行神经网络架构的一般蓝图[4]。
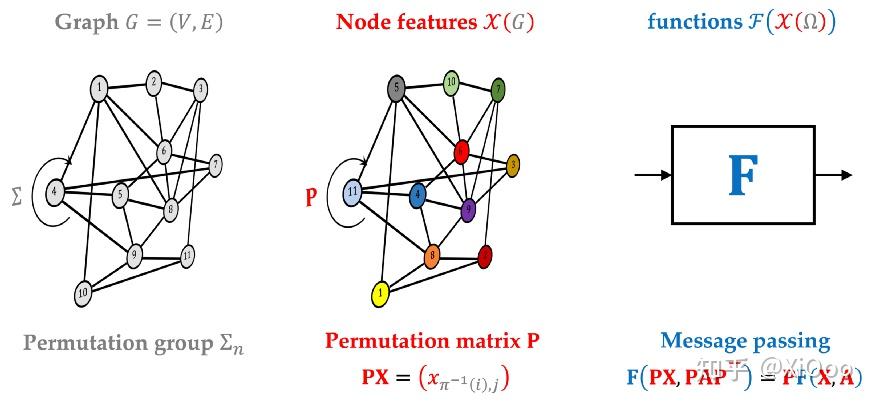
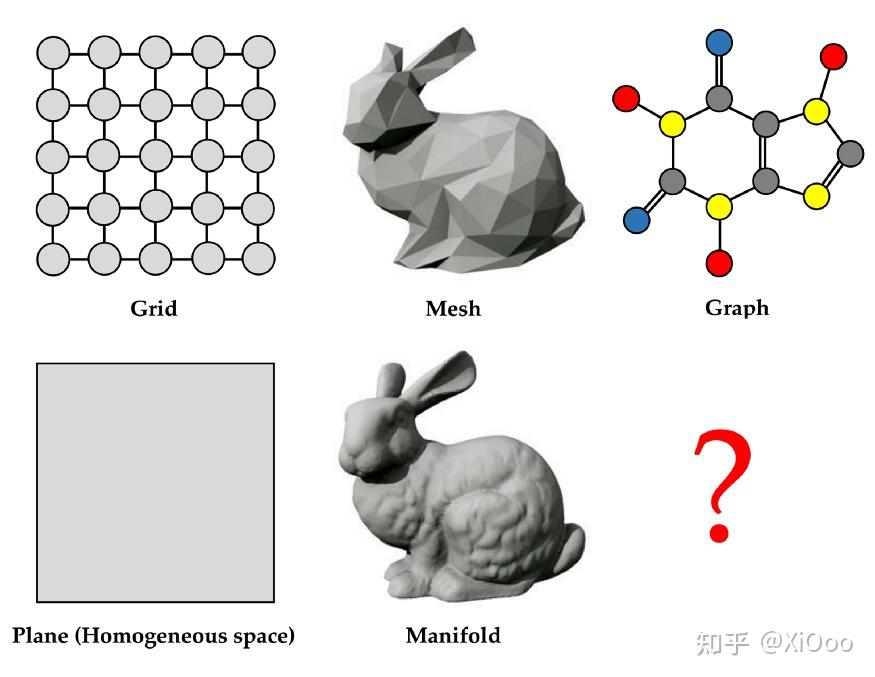
几何深度学习蓝图可以应用于不同的领域,例如结构化网格、非结构化网格或图[5]。 然而,虽然前两者有明确的连续型模拟对象(结构化网格可以被认为是欧几里德或更普遍的齐次空间如球体的离散化,而非结构化网格是二维流形的常见离散化),但对于图却没有明确的的连续模拟对象[6]。 这种不公平有点令人不安,并驱动我们仔细研究用于图学习的连续模型。
图神经扩散----图神经网络 (GNNs) 通过在图上执行某种形式的消息传递来学习,特征在点与点之间依靠边进行传播。 这种机制与图上的扩散过程有关,可以用偏微分方程 (PDE) 的形式表示,称为“扩散方程”。 在最近的一篇论文[7]中,我们展示了这种具有非线性可学习扩散函数的 PDE 的离散化(称为“图神经扩散”或 GRAND)概括了一大类 GNN 架构,例如图注意力网络(GAT)[8]。
PDE 思维方式提供了多种优势,例如可以利用具有保证稳定性和收敛特性的高效数值求解器(例如隐式、多步、自适应和多重网格方案)。 这些求解器中的一些在流行的 GNN 架构领域中没有直接的类比,可能有望带来新的有趣的图神经网络设计。 由于我们考虑的扩散 PDE 可以被视为某些相关能量的梯度流[9],因此此类架构可能至少比典型架构更易于理解。
同时,虽然 GRAND 模型在传统 GNN 的层位置提供连续时间,但方程的空间部分仍然是离散的并且依赖于输入图。 重要的是,在这个扩散模型中,域(图)是固定的,并且在其上定义的一些属性(特征)会演变。
微分几何中常用的一个概念是几何流,它演化域本身的属性[10]。 这个想法在 1990 年代被我的博士导师 Ron Kimmel 和他的合著者在图像处理领域采纳[11]。 他们将图像建模为嵌入在联合位置和颜色空间中的流形,并通过最小化嵌入的谐波能量的偏微分方程对其进行演化[12]。 这种称为贝尔特拉米流的 PDE 具有各向同性非欧氏扩散的形式,并产生边缘保留的图像去噪。
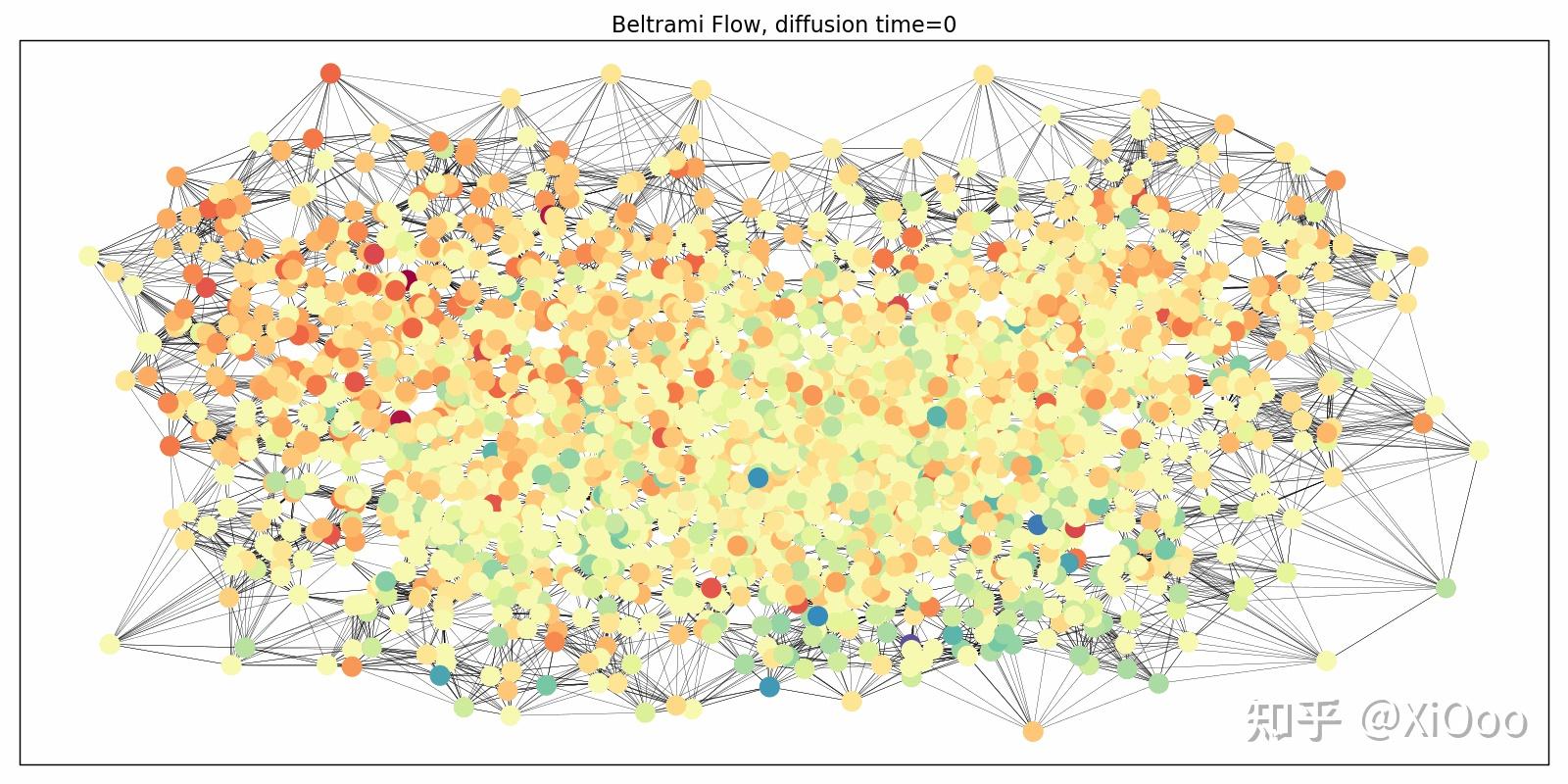
我们将此范式应用于“Beltrami 神经扩散”(BLEND)框架[13]中的图形。 图的节点现在以位置和特征坐标为特征,两者都是进化的,两者都决定了扩散特性。 在这种心态下,图本身变成了一个辅助角色:它可以从位置坐标生成(例如作为 k 最近邻图)并在整个进化过程中重新连接。 下图说明了这个同步进化过程:
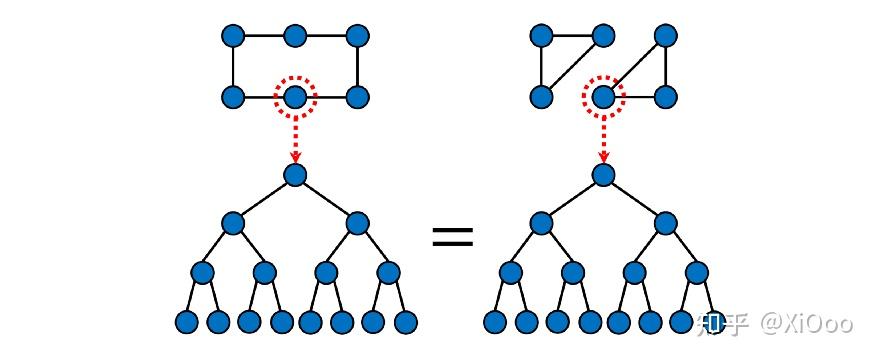
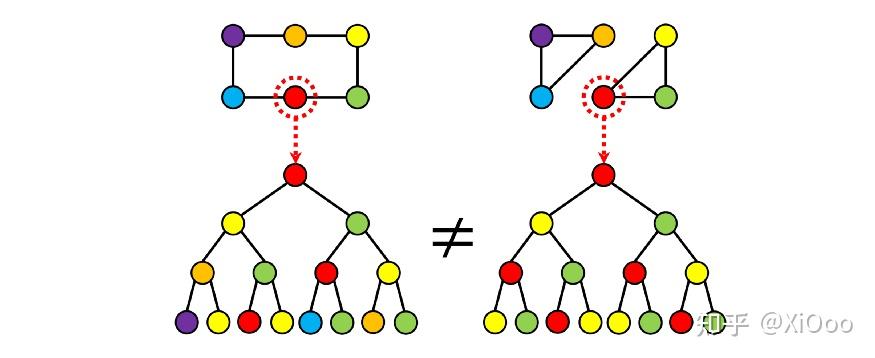
最近的工作格外关注图神经网络的表达能力问题。 消息传递 GNNs 等效于 Weisfeiler-Lehman 图同构测试[14-16],这是一种尝试通过迭代颜色细化来确定两个图在结构上是否等效(“同构”)的经典方法。 这个检验是必要但不充分的条件:事实上,Weisfeler-Lehman 可能认为一些非同构图是等价的。 下图说明了传递 GNN 的消息“看到”了什么:两个突出显示的节点看起来无法区分,尽管图显然具有不同的结构:
位置编码----解决此问题的常见方法是通过为节点分配一些表示图中节点的角色或“位置”的附加特征来“着色”节点。 在 Transformers[17](它是在完整图[4]上运行的注意力 GNN 的特例)中普及,位置编码方法已成为增加图神经网络表达能力的常用方法。
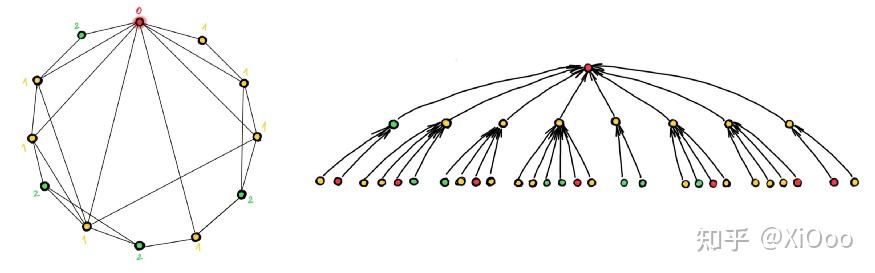
也许最直接的方法是赋予每个节点一个随机特征[18]; 然而,虽然更具表现力,但这种方法的泛化能力较差(因为不可能在两个图中重现随机特征)。 图拉普拉斯算子[19]的特征向量提供了图的邻域保留嵌入,并已成功用作位置编码。 最后,我们在与 Giorgos Bouritsas 和 Fabrizio Frasca[20]的论文中表明,图的子结构计数可以用作位置或“结构”编码的一种形式,可以证明它比基本的 Weisfeiler-Lehman 测试更强大。
然而,对于位置编码有多种选择,如何选择一个没有明确的方法,也没有明确的答案在哪种情况下哪种方法更有效。 我相信像 BLEND 这样的几何流可以根据这个问题来解释:通过非欧式扩散演化图的位置坐标,位置编码适用于下游任务。 因此,答案是“视情况而定”:最佳位置编码是手头数据和任务的函数。
高阶消息传递----表达性的另一种选择是停止从节点和边的角度考虑图。 图是被称为细胞复合体的对象的例子,细胞复合体是代数拓扑领域的主要研究对象之一。 在这个术语中,节点是 0-cells,边是 1-cells。 不必止步于此:我们可以构建如下图所示的 2 个单元格(面),这使得我们之前示例中的两个图完全可区分:

在最近与 Cristian Bodnar 和 Fabrizio Frasca[21-22]合着的两篇论文中,我们表明有可能构建一种“提升变换”,用这种高阶单元来增强图,在其上可以执行更复杂的形式 的分层消息传递。 这个方案可以证明比 Weisfeiler-Lehman 测试更具表现力,并且在计算化学中显示出有希望的结果,其中许多分子表现出更好地建模为细胞复合物而不是图形的结构。
GNNs 的另一个常见困境是“过度挤压”现象,或者由于输入图的某些结构特征(“瓶颈”)而导致消息传递无法有效传播信息[23]。 过度挤压通常发生在体积呈指数增长的图中,例如小世界网络[24]以及依赖于远程信息的问题。 换句话说,GNN 在其上运行的输入图并不总是对消息传递友好。
过度挤压、瓶颈和图重绘----根据经验,观察到将输入图与计算图解耦并允许在不同的图上传递消息有助于缓解问题;这种技术通常被称为“图重绘”。
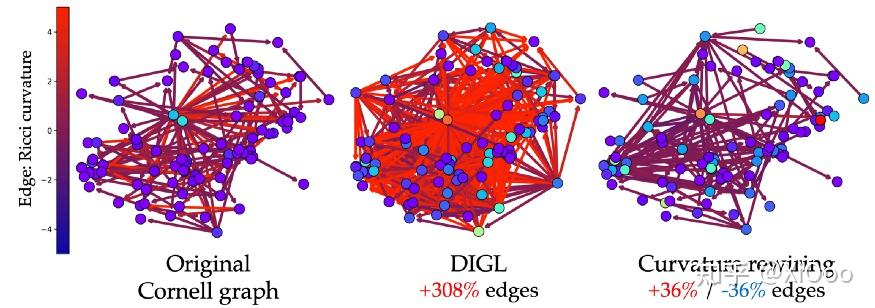
公平地说,许多流行的 GNNs 架构都实现了某种形式的图重新布线,可以采用邻域采样(最初在 GraphSAGE 中提出以应对可扩展性[25])或多跳过滤器[26]的形式。上面讨论的拓扑消息传递也可以看作是一种重新布线的形式,从而可以通过高阶单元“捷径”地在远距离节点之间传输信息。 Alon 和 Yahav[23]表明,即使像使用全连接图这样简单的方法也可能有助于改善图机器学习问题中的过度挤压。 Klicpera 和合著者热情地宣称“扩散改进了图学习”,提出了 GNNs(称为“DIGL”)的通用预处理步骤,包括通过扩散过程对图的连通性进行去噪[27]。总体而言,尽管进行了重要的实证研究,但过度挤压现象一直难以捉摸且理解不足。
在最近的一篇论文[28]中,我们表明导致过度挤压的瓶颈可归因于图的局部几何特性。 具体来说,通过定义 Ricci 曲率的图类比,我们可以证明负弯曲的边是罪魁祸首。 这种解释导致了类似于“反向 Ricci 流”的图形重新布线程序,该程序通过外科手术去除了有问题的边,并生成了一个更适合消息传递的图形,同时在结构上与输入的图形相似。
这些例子表明微分几何和代数拓扑为图机器学习中的重要和具有挑战性的问题带来了新的视角。 在本系列的后续文章中,我将更详细地展示如何使用这些领域的工具来解决图神经网络的上述问题。 第二部分将讨论代数拓扑如何提高 GNN 的表达能力。 第三部分将处理几何扩散偏微分方程。 第四部分将展示过度挤压现象如何与图曲率相关,并提供一种受 Ricci 流启发的图形重新布线的几何方法。
[1]H. Weyl, Symmetry (1952), Princeton University Press.
[2]F. Klein, Vergleichende Betrachtungen über neuere geometrische Forschungen (1872).
[3]J. Schwichtenberg, Physics from symmetry (2018), Springer.
[4]M. M. Bronstein, J. Bruna, T. Cohen, and P. Veli?kovi?, Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges (2021); see an accompanying post and the project website.
[5]In the above GDL proto-book, we call these the “5G” of Geometric Deep Learning.
[6]Geometric graphs naturally arise as discrete models of objects living in a continuous space. A prominent example is molecules, modeled as graphs where every node represents an atom with 3D spatial coordinates. On the other hand, it is possible to embed general graphs into a continuous space, thus (approximately) realising their connectivity using the metric structure of some space.
[7]B. Chamberlain, J. Rowbottom et al., GRAND: Graph Neural Diffusion (2021) ICML.
[8]P. Veli?kovi? et al., Graph Attention Networks (2018) ICLR.
[9]A gradient flow can be seen as a continuous analogy of gradient descent in variational problems. It arises from the optimality conditions (known in the calculus of variations as Euler-Lagrange equations) of a functional.
[10]Geometric flows are gradient flows of functionals defined on manifolds. Perhaps the most famous of them is the Ricci flow, used by Grigori Perelman in the proof of the century-old Poincaré conjecture. Ricci flow evolves the Riemannian metric of the manifold and is structurally similar to the diffusion equation (hence often, with gross simplification, presented as “diffusion of the metric”).
[11]N. Sochen et al., A general framework for low-level vision (1998) IEEE Trans. Image Processing 7(3):310–318 used a geometric flow minimising the embedding energy of a manifold as a model for image denoising. The resulting PDE is a linear non-euclidean diffusion equation ?=Δx (here Δ is the Laplace-Beltrami operator of the image represented as an embedded manifold), as opposed to the nonlinear diffusion ?=div(a(x)?x) used earlier by P. Perona and J. Malik, Scale-space and edge detection using anisotropic diffusion (1990) PAMI 12(7):629–639.
[12]Beltrami flow minimises a functional known in string theory as the Polyakov action. In the Euclidean case, it reduces to the classical Dirichlet energy.
[13]B. P. Chamberlain et al., Beltrami Flow and Neural Diffusion on Graphs (2021) NeurIPS.
[14]B. Weisfeiler, A. Lehman, The reduction of a graph to canonical form and the algebra which appears therein (1968) Nauchno-Technicheskaya Informatsia 2(9):12–16.
[15]K. Xu et al., How powerful are graph neural networks? (2019) ICLR.
[16]C. Morris et al., Weisfeiler and Leman go neural: Higher-order graph neural networks (2019) AAAI.
[17]A. Vaswani et al., Attention is all you need (2017) NIPS.
[18]R. Sato, A survey on the expressive power of graph neural networks (2020). arXiv: 2003.04078. Uses random features for positional encoding.
[19]V. P. Dwivedi et al. Benchmarking graph neural networks (2020). arXiv: 2003.00982. Uses Laplacian eigenvectors as positional encoding, though the idea of spectral graph embedding is way older and has been widely used in nonlinear dimensionality reduction such as the classical work of M. Belkin and P. Niyogi, Laplacian eigenmaps and spectral techniques for embedding and clustering (2001), NIPS.
[20]G. Bouritsas et al., Improving graph neural network expressivity via subgraph isomorphism counting (2020). arXiv:2006.09252. Uses graph substructure counts as positional encoding; see an accompanying post.
[21]C. Bodnar, F. Frasca, et al., Weisfeiler and Lehman go topological: Message Passing Simplicial Networks (2021) ICML.
[22]C. Bodnar, F. Frasca, et al., Weisfeiler and Lehman go cellular: CW Networks (2021) NeurIPS.
[23]U. Alon and E. Yahav, On the bottleneck of graph neural networks and its practical implications (2020). arXiv:2006.05205
[24]In such graphs, the size of neighbours up to k-hops away grows very fast with k, resulting in “too many neighbours” that have to send their updates to a node.
[25]W. Hamilton et al., Inductive representation learning on large graphs (2017) NIPS.
[26]Frasca et al., SIGN: Scalable Inception Graph Neural Networks (2020). ICML workshop on Graph Representation Learning and Beyond. Uses multihop filters; see an accompanying post.
[27]J. Klicpera et al., Diffusion improves graph learning (2019) NeurIPS. Rewires the graph by computing Personalised Page Rank (PPR) node embedding and then computing a k-NN graph in the embedding space.
[28]J. Topping, F. Di Giovanni, et al., Understanding over-squashing and bottlenecks on graphs via curvature (2021).
感谢 Cristian Bodnar、Ben Chamberlain、Fabrizio Frasca、Francesco Di Giovanni 和 Nils Hammerla 校对这篇文章。 有关图上深度学习的其他文章,请参阅我在 Towards Data Science 中的其他文章,订阅我的专栏,获得 Medium 会员资格,或在 Twitter 上关注我。
电 话:400-123-4567
传 真:+86-123-4567
手 机:13800000000
邮 箱:admin@eyoucms.com
地 址:广东省广州市天河区88号


 简体中文
简体中文
 English
English