


AdaBelief 也算最近看的很有意思的论文,作者分析做的很好,实验效果也挺好,大家关注度也比较高,而且后面还有意外惊喜。

尽量从没太多人写的角度来写,而非复述论文。介绍这篇的文章很多,甚至作者在 B 站还有中文介绍视频。
介绍 AdaBelief 前,先需要简单介绍下 SGD(随机梯度下降)和 Adam,因为论文中一直说的都是 AdaBelief 的最大优点就是集以上两者的优点为一身。
在论文中,以及 Github 页面作者分享了很多实验结果来证明这几点,看上去 AdaBelief 好像是一个完美的优化器,而且理论方面也如作者说的,正是因为 Belief 的存在,所以 AdaBelief 才能表现如此好。但仔细观察实验结果,还有一些细节部分,就会发现事情或许并非如此。
SGD 算是机器学习第一课里的知识了,相信大部分同学也都很清楚其方法:根据损失函数给模型每个参数计算梯度,之后在梯度方向更新一小步。当然这只是 GD,还有 S(Stochastic),为提高效率,随机选择训练样本(一般为 batch),直到训练模型到一个满意的结果。
方程也很简单。
是参数, 是学习率,而 当然就是梯度。
虽然 SGD 算法很简单,而且都差不多70年前提出的算法。但因为其良好的泛化性,在某些任务上(特别是 CV 大规模数据集,比如 ImageNet)仍然还得到应用。
在某些领域,SGD (如 LARS 和 LAMB)的一些变种最近也得到很多应用,之前自监督学习那篇 BYO L 就是 LARS 训的。
但从方程里也能看出,SGD 是对全局参数用一个学习率,而其实真正优化更想要让那些梯度方向稳定的参数更新更快,而不稳定的更新步伐更小。因此这也导致 SGD 算法训练不太稳定,收敛慢(尤其训练早期)。
对于上面这点问题,就有人提出了适应性法(Adaptive Method),能针对各个参数计算出其定制化的学习率,进行更新训练。此类优化算法很多(名字带 Ada 的都是),而 Adam 就是其中的佼佼者。
Adam 因其万金油性,导致现在整个领域大部分任务都直接无脑就用,直接默认用 Adam。前段时间还看过一个说法,因为 Adam 的普及性,整个领域大部分模型是用 Adam 训练的,改进模型也都用 Adam,因此整个领域很可能过拟合了,过拟合到 Adam 优化器上了,这些模型只对 Adam 优化有效.
Adam 相对 SGD 主要是加了两个参数,分别为梯度的一阶动量 (Momentum)和二阶动量 ,计算方法如下(暂时先略过 Bias Corrrection 项,下同)
其中 和 是两个超参数,一般默认 0.9 和 0.999,但一些大佬能根据任务来调。
而 Adam 梯度更新方程是
是个很小的数,一般不用调,但根据 Tensorflow 文档有时候也能调,来获得更好表现,比如在 ImageNet 上训 InceptionNet.
介绍完 SGD 和 Adam,终于快说到正主 AdaBelief 了。AdaBelief 也是种适应性算法,在 Adam 上的改动很小,而效果却不一般,那这个改动是什么呢?
当然是信仰(belief),咸鱼有了信仰都不一样,更别说优化器。
而这个所谓信仰其实就是,当前梯度与其滑动平均差值的二阶动量(一个很长的信仰),其实可以理解成梯度方差。
信仰又是什么
上面提到给优化器加入信仰的大概思想是:将滑动平均 看作是梯度的预测,如果当前梯度 偏离了 那么说明当前 是个不坚定的信徒,虽然不会送宗教裁判所,但这里就给它一个比较小的学习率;而如果 接近 就说明当前 是一个坚定的信徒,要大大的奖励,给更大的学习率。
实际上是为了解决下面这张图中的第三种情况。

梯度大而方差小的情况下,因为 Adam 二阶动量参数 的原因反而会导致学习率小,而实际上这是不合适的。但 AdaBelief 在这种情况却还会继续用大学习率,继续进军。
介绍这么多,改进方程也就很简单了,对比 Adam 只用将
替换成
算了下加上复制粘贴输入这个公式总共才用了六步。
最后的参数更新方程将 替换成 就行了
非常简单。
信仰的力量:实际效果
论文中除了上面的 Intuition,还对 AdaBelief 的收敛性进行了理论分析,还有大量图片视频展示优化过程。
但我比较关心的是在具体问题上的效果。
首先是 CNN 模型的图片分类任务,用 ImageNet 上 ResNet 18 来展示

可看到在准确性上 AdaBelief 超过了其他适应性方法,比 SGD 差一点点,但同时因为是适应性算法,它的收敛速度比 SGD 要快。
之后是 LSTM 的语言模型任务,具体用 LSTM 在 Penn TreeBank 上的展示

发现模型越复杂(层数越多),AdaBelief 的性能就越好,收敛速度和效果都挺好。
接着是 GAN 的训练,主要因为 GAN 训练对稳定性要求很高,所以这里准备测试 AdaBelief 的稳定性。当然结果发现也是效果比其他都要好。而且看图上 FID 分数的方差波动也很小,说明很稳定。
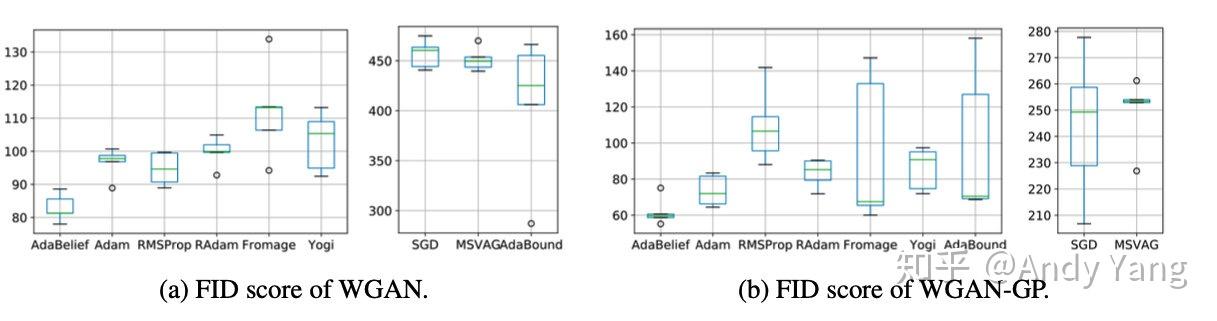
以上就是论文中展示的所有实验分析了,但是...
Where is Transformer?! and pretrain model

果然还是有人有同样想法,所以在 Github 库里找到 Transformer 相关的实验。
但只在翻译任务上跑了一下,结果看起来说服力不大,只在小数据集 ISWLT14 上进行了实验

看上去是有些提升,但还是感觉没说服力,因为 Transformer 也是被证实了大量级会更有效,但这方面实验没做。预训练模型上也没有进行实验。
即使如此,作者是展示了理论分析,又展示了实验结果,看上去好像很有说服力了,但是慢着,如果现在告诉你很有可能上面说的所谓的“信仰”都是扯淡,可能效果并没分析那么大,效果的产生在其他地方,你会怎么想?
一顿操纵猛如虎,结果带来效果产生跟操纵却没太大关系。
信仰的破灭?The Epsilon
第一遍看论文并没有注意这个问题,直到在 Github 库里看到关于 epsilon (即 ) 参数分析时,才注意到这一点。
前面理论分析略过了 Bias Correction (偏差校正)项,但现在这里要说,这个在文中被因为简便而略过的部分,很有可能这才是整篇论文的关键

注意在 AdaBelief 中除了取代 ,还做了步额外的操作,而文中只稍稍提了下为什么这样操作
in order to better match the assumption that is bouded below (the lower bound is at leat ε)
为了更好的满足 有下界的条件(下界最少是 )
而实验结果却表明就是这样一个小小的 对优化器效果影响却非常大。
如果需要 AdaBelief 偏向 SGD 有更多泛化性,那么就给 调大,反之,需要 AdaBelief 偏向适应性优化器的话,就给 调小。这也符合前面说的 AdaBelief 是一个能同时拥有两边优点的优化器设定。
但是,好奇的同学肯定就问了,明明之前说的主要 idea 是给 替换成了 ,但怎么感觉这里都没有 的戏,一个小小的 反而喧宾夺主了。
进一步来说,既然 看起来好像并不是很重要,那如果对 Adam 进行同样操作,加入同样 的话,是不是 Adam 也能获得类似的效果。事实正是如此。
这样想的人并非只是我们,已经有人做了。这便是论文 EAdam Optimizer: How ε Impact Adam 所提出的,它所做的就只是如刚才说的,也在 Adam 偏差校正的地方加了个,即
那么这个 EAdam 效果如何,特别是和 AdaBelief 的对比。
首先是 CNN 图片分类(EAdam 是图中红线,AdaBelief 是绿线)

接着是 LSTM 语言模型

还在目标检测上跑了 Faster-RCNN+FPN

结果发现, EAdam 大多情况下和 AdaBelief 性能差不多!
差也只略差一点。因此可以说,其实 才是关键,即使只是小小的更换了一个位置。这里 AdaBelief 犯了一个对比实验中的大错误,没有保证两种实验条件除了一处改动外其他条件都相同(这里有两处改动),而有效果之后归因也出现了错误。
AdaBelief 所声称的 belief(信仰)可能起得作用并不是很大,AdaBelief 更应该叫做,。
因此这里我们是否可以说这是,信仰的破灭呢?
当然之前理论分析中的第三种情况,我也是认同 是优于 的,但很有可能在整个优化过程中,第三种情况并不多吧,这也导致 真正起的作用并不是太大。
如果感兴趣,大家可以自己推导一下公式对比分析下 AdaBelief,Adam,EAdam 这三个。当然如果我有时间,也可以推导后写一篇。
Reference
电 话:400-123-4567
传 真:+86-123-4567
手 机:13800000000
邮 箱:admin@eyoucms.com
地 址:广东省广州市天河区88号


 简体中文
简体中文
 English
English